Getting Started
This guide explains how to use the core search and analysis features in Krugle V5. These features apply to all instances of Krugle V5 (including Krugle Enterprise, Krugle Opensearch and Krugle Basic), but the instruction herein explicitly reference Krugle Basic. This is because Krugle Basic comes pre-configured with information and code projects that allow you to perform the examples in this guide.
Sample Projects
Let’s first take a look at the sample projects commonly included with Krugle Basic, which can be accessed by clicking on the "Browse Projects" link to the right of the search box. The available projects include:
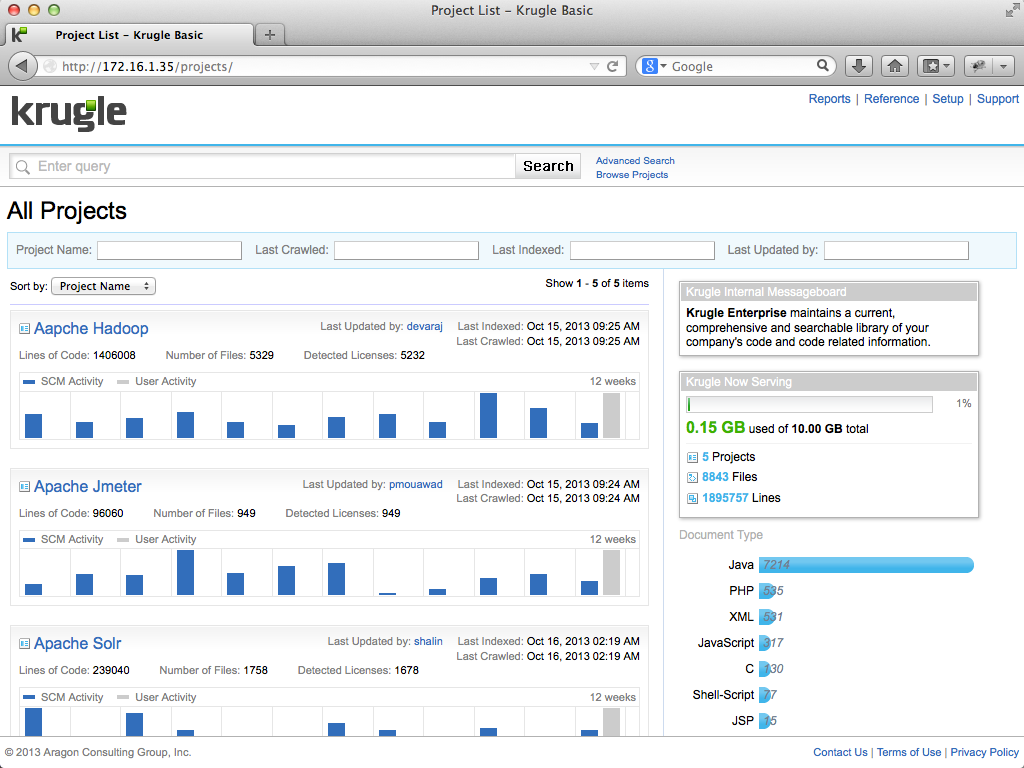
Beyond these simple examples, Krugle projects are extremely flexible and can be configured by the Krugle administrator. The administrator can also choose the set of users who may access or search projects and the frequency with which projects are re-crawled to ensure updates are added to the index. In addition, Krugle will crawl the check-in comments for projects and make these searchable too.
Code & Document Search
To search for a keyword in Krugle Basic, simply enter that string in the search box. In the example below, we have searched for "getParameter":
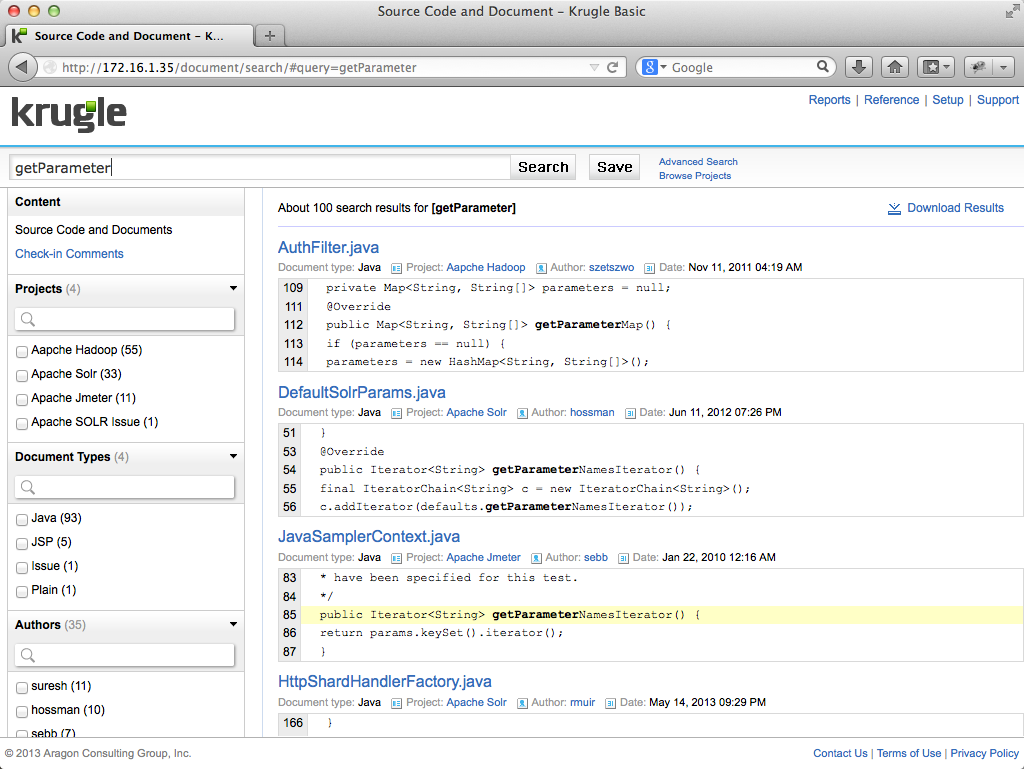
Search results are shown 10 per page and each result includes the name of the file, the language, the project name, when the project was last crawled, and a 5 line snippet from the file that shows the best matches from that file, and with the search term highlighted.
The search may be refined using the facets in the left-hand margin: by Project, by Document Type, by Author or by Date. In the example below, we have refined the search to return only results where "getParameter" is found in Java files within the project "Apache SOLR":
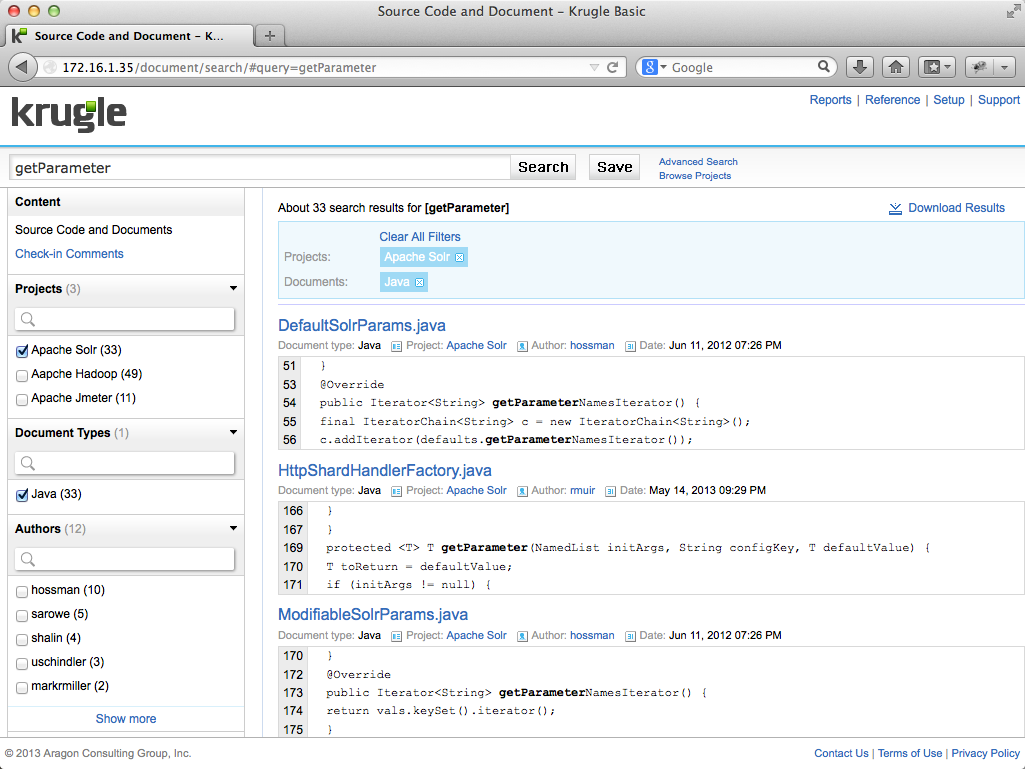
Searches may also be refined by using directives entered into the search box that allow you to take advantage of the code parsing capabilities of Krugle. For details of these, please consult the Krugle Enterprise User Manual.
Note that every set of search criteria generates a unique URL, which can be saved for later use of shared with colleagues. When a user clicking on a search URL, their browser will open an instance of the Krugle Enterprise web client and execute the specified search, returning results from projects that the given user has access to.
These URLs enable the user to take advantage of browser tabs to display multiple search results by simply opening search results in a new tab. Generally, new browser tabs can be opened on Windows via Ctrl+Click on Windows and via Command+Click on a Mac.
Clicking a file name opens the file in the browser and shows the location of the file within the project:
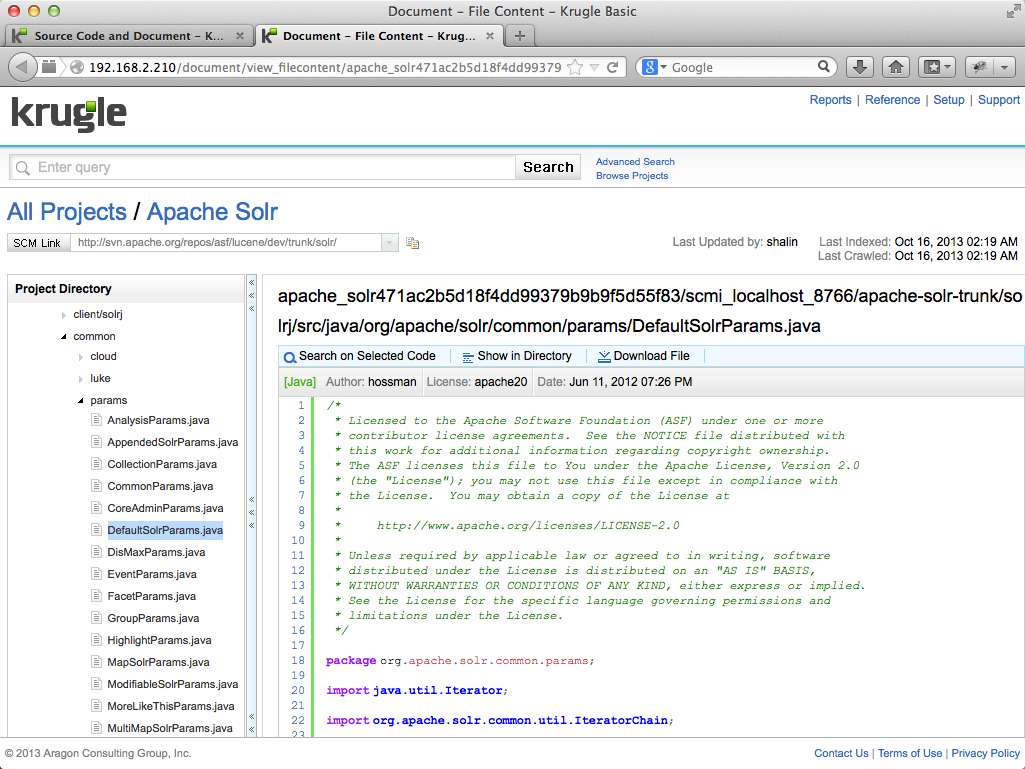
Krugle has built-in MIME-type detection that distinguishes between over 50 programming, scripting and markup languages as the files are crawled out of the SCM repositories. In all cases throughout the Krugle interface, slicking on the project name from the search results or from the file display will open the Project Overview page for the project (see later section).
Advanced Code Search
A powerful Krugle feature is the ability to create searches that exploit the underlying structure - and design intent - of the software code. These searches can be created with Krugle query qualifiers. Krugle query qualifiers make your searches more accurate and effective.
For example, you can use Krugle to locate keywords or "tokens" in very specific portions of the code: in comments that are included with the code files, in function or class names or in function calls, in object methods, etc. For example, to find all files that had an occurrence of the term Connection contained in a function call sequence of code, you would enter the search query functioncall:"Connection" in the Krugle search box.
A complete list of advance Krugle query qualifiers and examples can be found here.
Issue Search
The Krugle Basic instance includes a project that contains only entries from the JIRA bug tracking system. Krugle indexes these records and makes information such as the issue summary, description and created/modified dates searchable too. Issues are classified as a special document type named "Issue", which allows searches to be narrowed to include just Issues by clicking on the appropriate facet, as well as restricting searches by author, data and project as normal.
In the example below, the user is searching for lang:issue (search file type "Issue") associated with the user "Robert Muir":
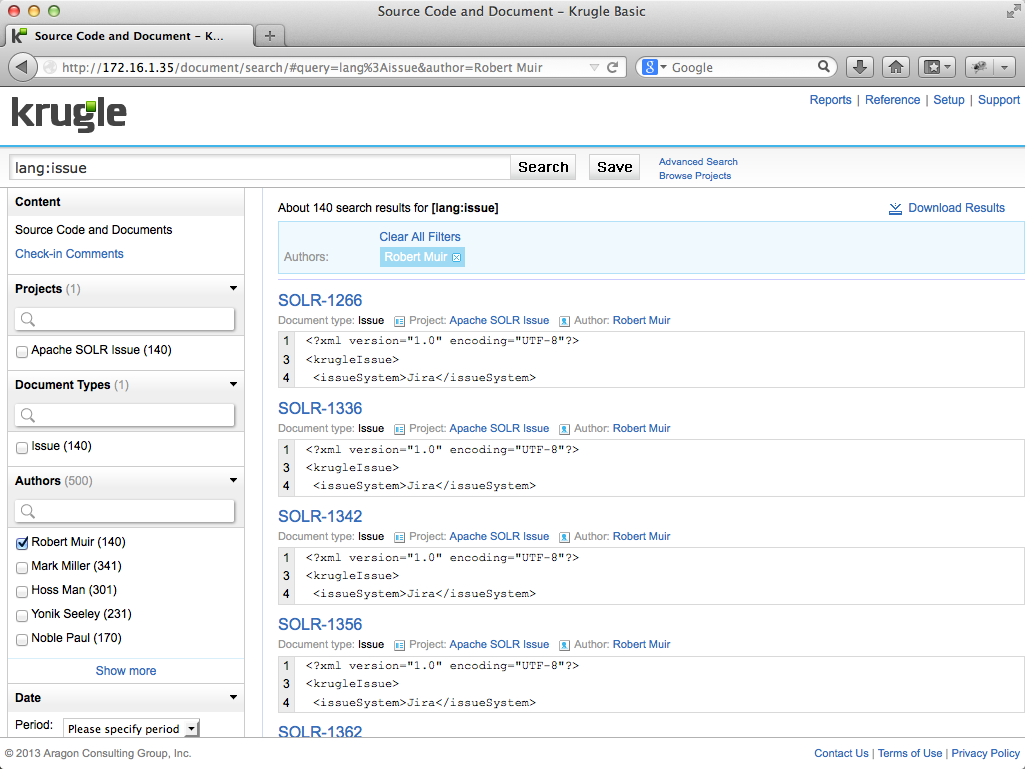
Clicking on the second result (SOLR-1336) displays the Issue detail page
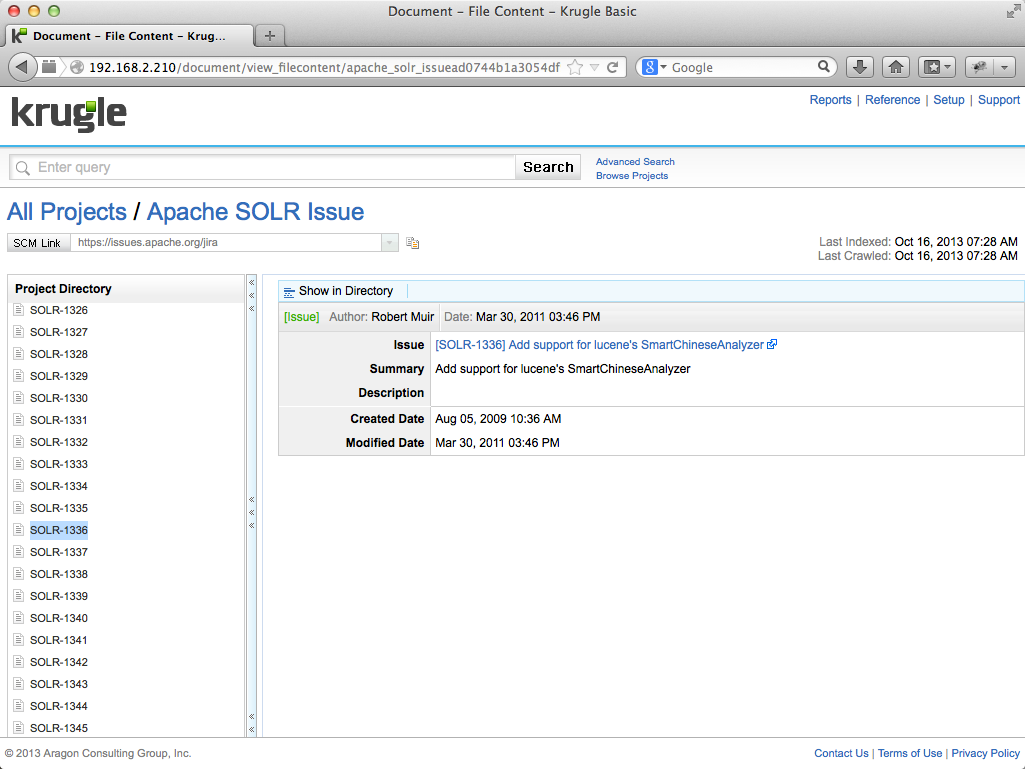
Notice that the issue page includes a URL to the original source issue, which can also be explored:
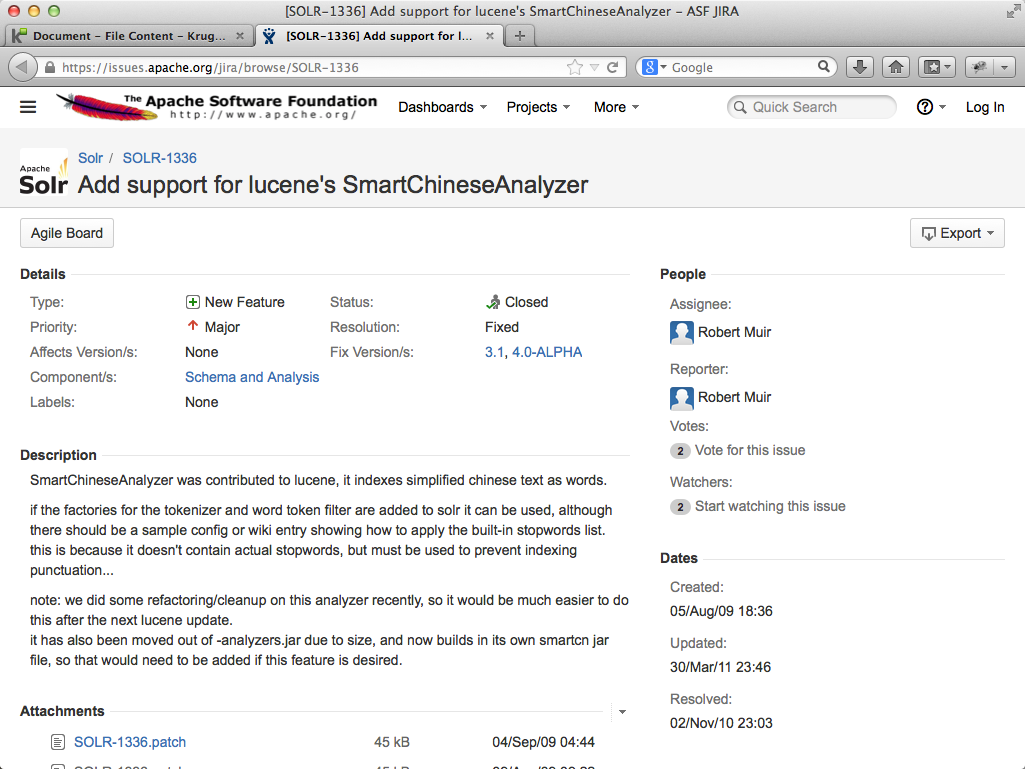
Check-In Comment Search
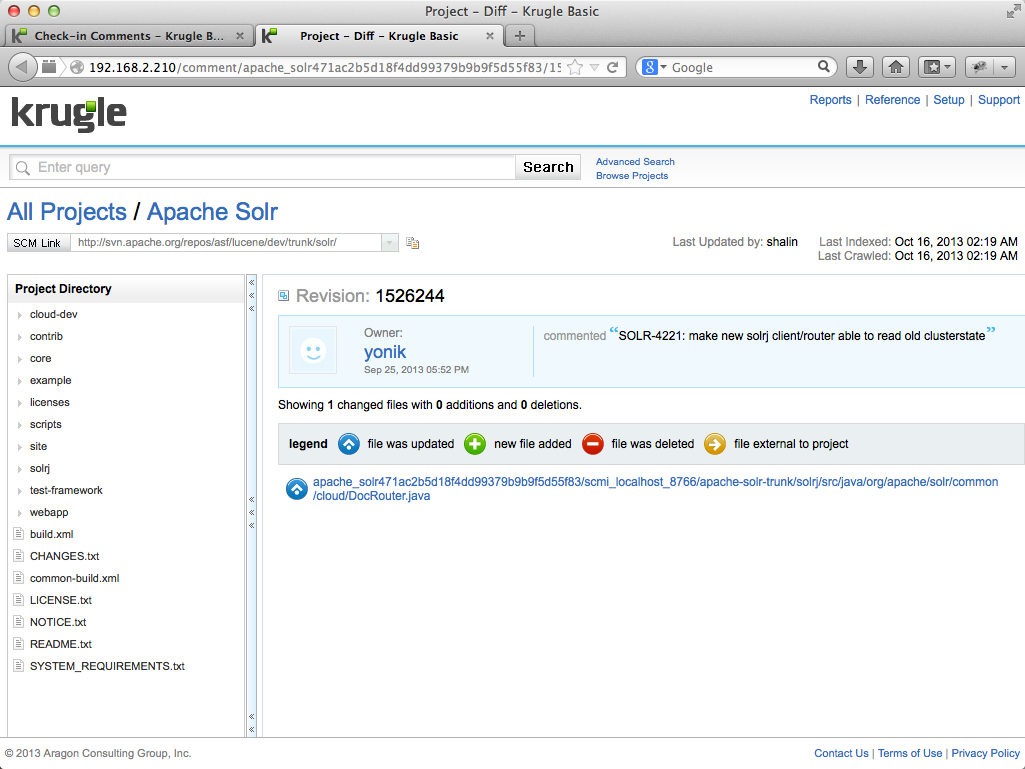
When Krugle Basic crawls projects it also crawls and indexes the entire check-in comments for the project and makes this searchable too. This is extremely useful for finding the set of changes that related to fixing a given bug or activities for a particular user. In the example below, we have searched for a specific bug id and Krugle Enterprise has returned a single result which has the search term in the check-in comment. By clicking on the revision ID we can then explore the details of the change set.
In the example below, the user searches for a reference to a bug ("SOLR 4221") in a "Check-in Comment" for the user "yonik". The result shows the check-in comment, the Subversion revision id of the commit, and the number of files that comprised the change set:
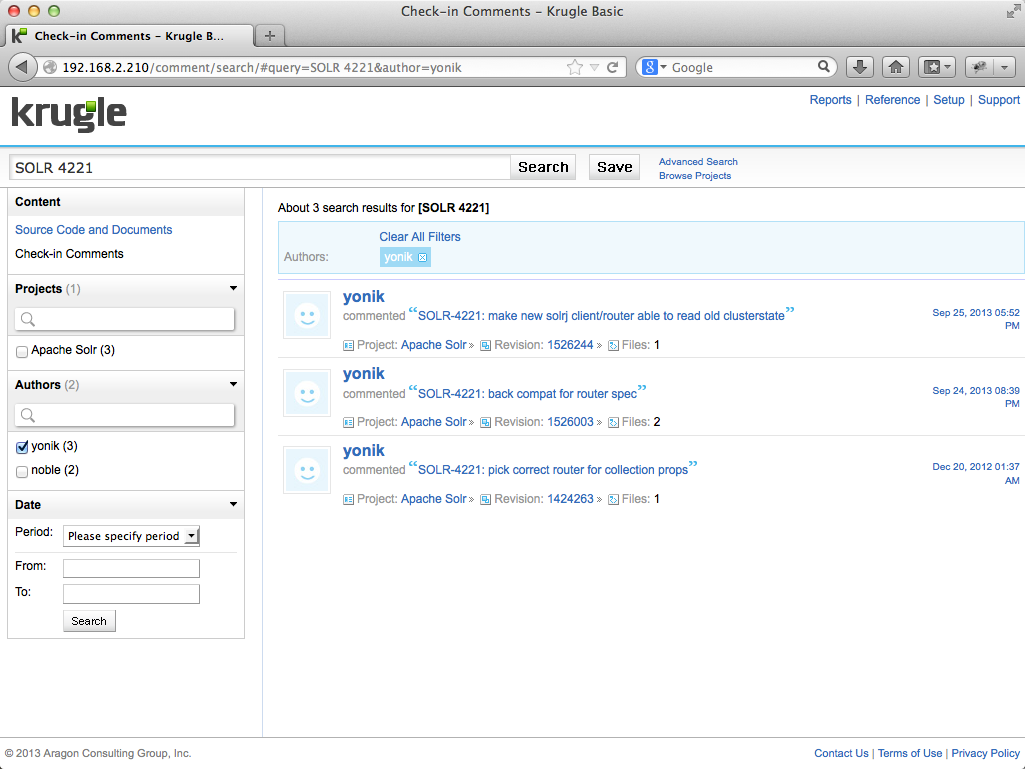
Clicking the revision number ("1526244" in this case) in the summary for the first result takes the user to a page summarizing the commit. The page lists the files added, deleted or modified by the commit:
New - Krugle AutoSearch™
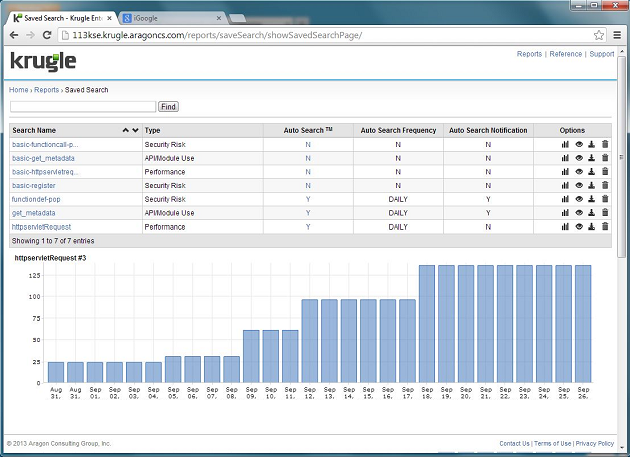
Krugle AutoSearch™ automatically prepares summary trend data for any Krugle query. This feature can be combined with all Krugle query and faceting options - making it possible to continuosly analyze and automatically report on a wide range of development activities.
For example, you may want to track the number of instances of a Java code pattern (e.g. method called with specific options) that results in poor performance or a memory problems - across all current projects. Or maybe you want to monitor all code submits that include a reference to "level 4" defect fixes across several, selected projects.
To begin, enter any query - as described in the preceding sections - and select the "Save" button. In the resulting dialog, enter a "Name" for your search and select a "Type" from the dropdown list - then click Save. Next, click Saved Search from the Reports link in the upper right portion of your screen. Click the detail icon (it looks like a human eye) in the Options column, from the row corresponding to the Search Name created in the previous step.
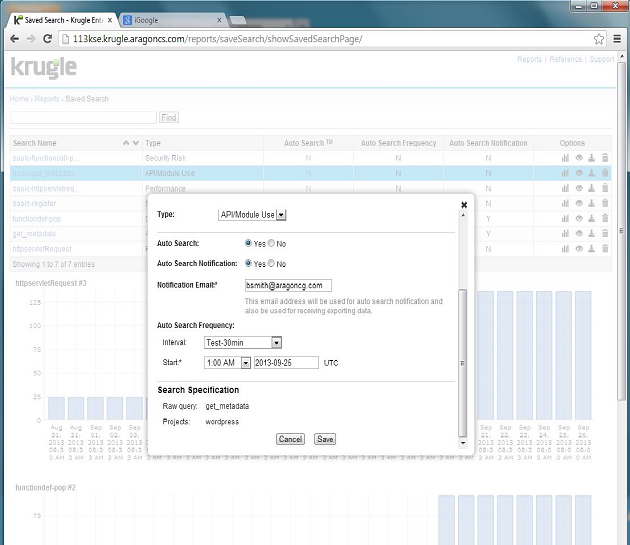
When the details dialog appears for your Search Name, click the edit icon in the upper right. Click the AutoSearch™ Yes choice. Specify a Frequency Interval (DAILY is usually sufficient), a desired start time and an email address where you want reports sent. Check the AutoSearch notification if you want to be notified whenever there is a change in results. Click Save when complete.
Once this specification is complete, Krugle will automatically run the query at the specified frequency, store/summarize query results and identify result changes since the query was last executed. Changes will be noted and results will be plotted in charts, as shown in the first screenshot of this section.
NOTE: Krugle will require several days after initial installation for AutoSearch™ results to populate.
Project Pages
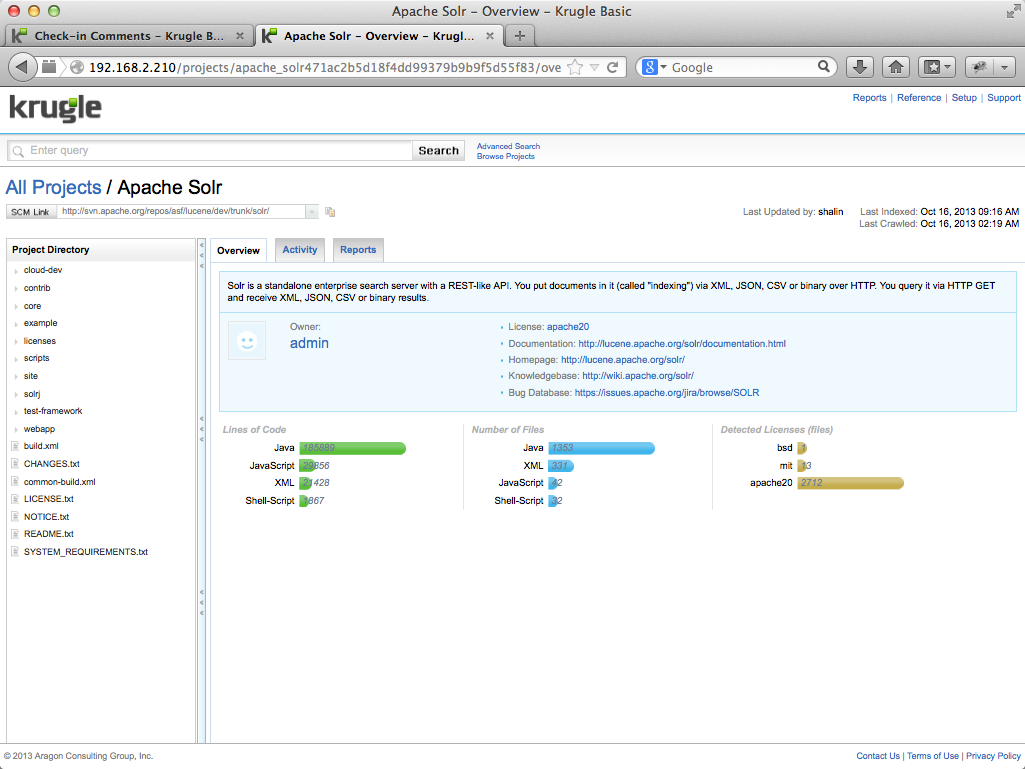
Clicking on a project’s name will open the Project Overview page for that project, which displays a range of information:
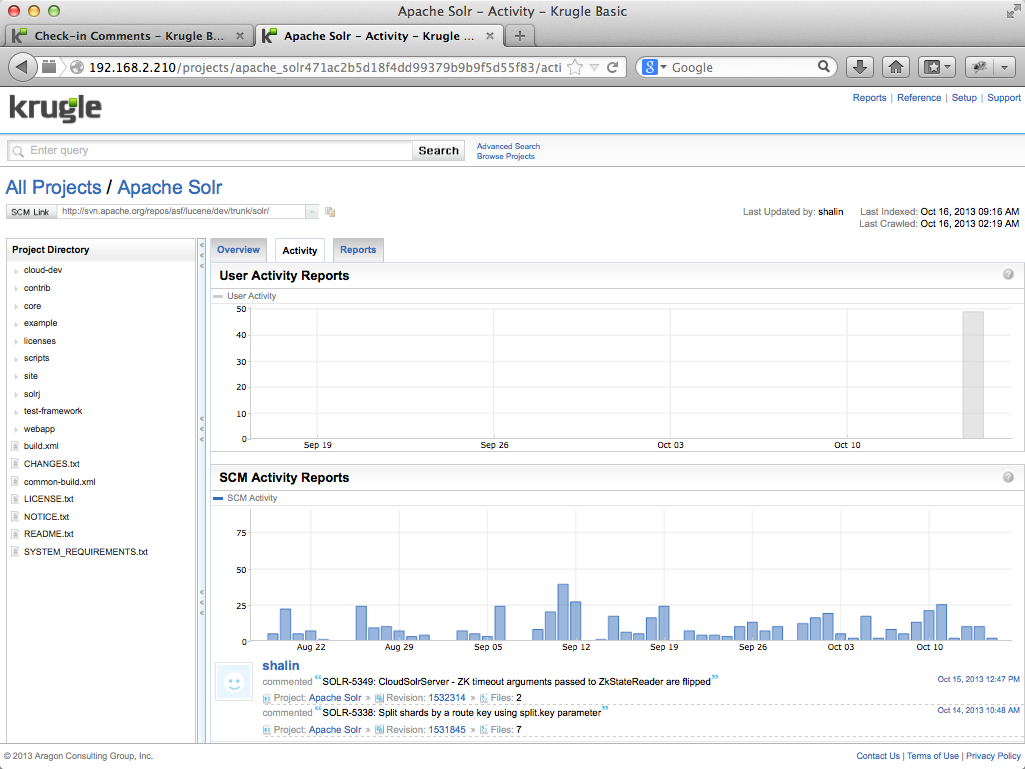
Clicking on a bar of the chart presents additional information. In the image below, we see details for check-ins on April 1. NOTE: the date ranges and data for your version of Krugle Basic will vary from the information shown here.
Clicking on the Revision number for any of the commits on a given day will open the change set page for that commit (see Check-In Comment Search section above).
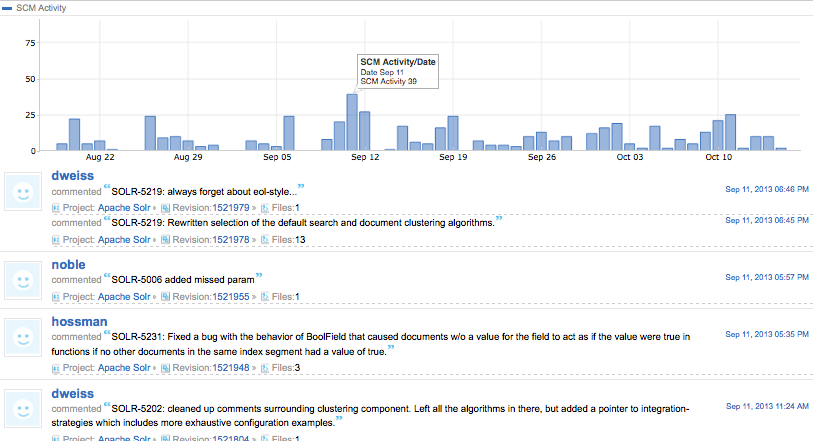
In this Krugle Basic instance a Similarity Report has been configured to compare the "Apache SOLR" project (which comprises code) with the "Apache SOLR Issue" project (which comprises issues):
This is a demonstration example only; although the two projects are not at all similar, the Similarity Report also compares the files within the reference project against other files within the same project.
The information contained in Similarity Reports can be applied in a number of ways, including:
The figure below shows the Similarity Report which begins with two charts. The first chart shows the total number of files from "Apache SOLR" that are similar to files in the other projects, grouped by similarity category. The second chart shows a breakdown of similarity by project. Note that the first bar compares the "Apache SOLR" project against itself, which indicates that even with this project there are some near identical files, which may point to an opportunity to re-factor some code.
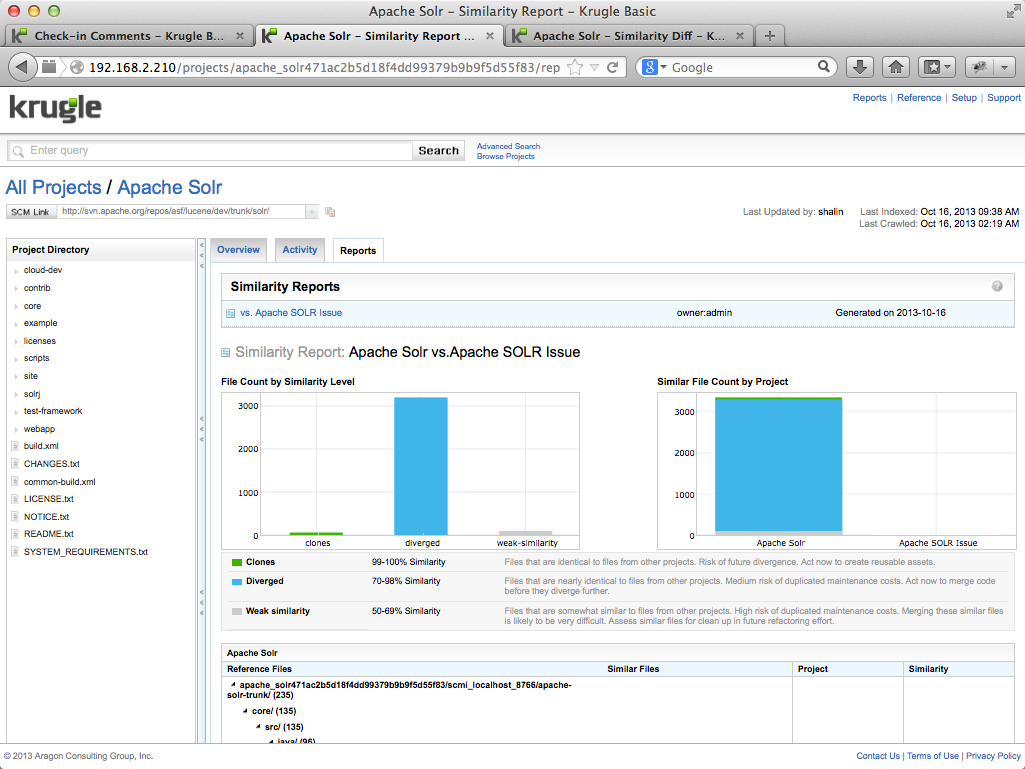
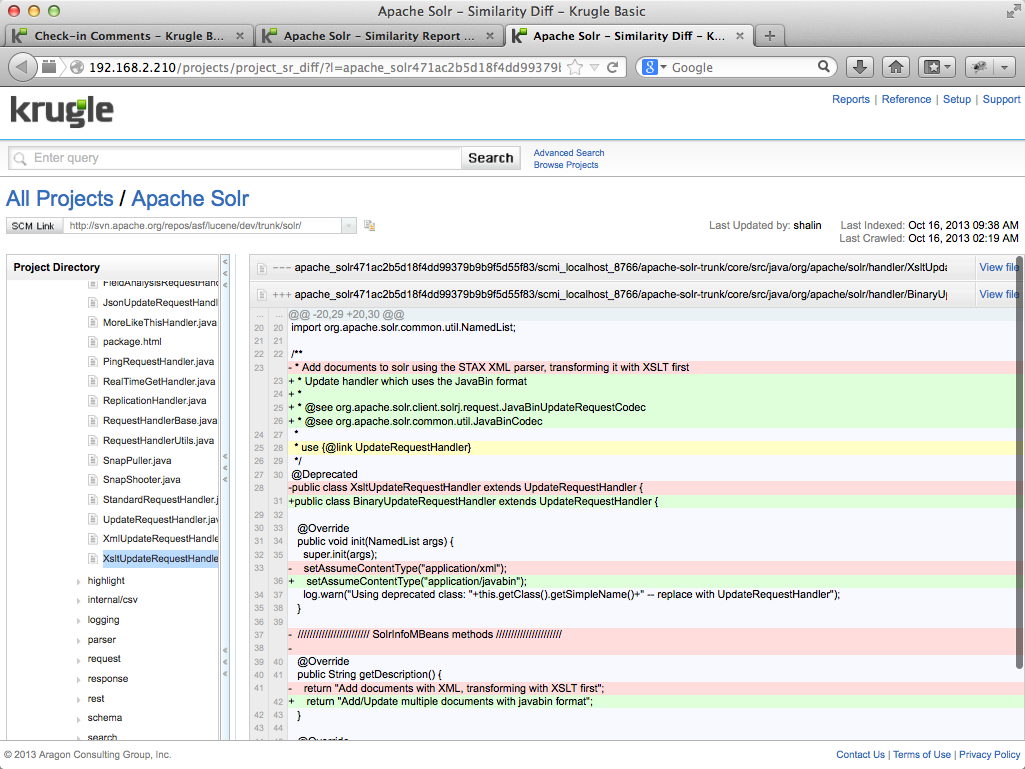
Below the charts is a table that shows similar file pairs across the set of projects. The table expands to show files from the reference project that are similar to files in the comparison set. The final column shows the degree of similarity as a percentage; if the similarity is less than 100%, clicking the link will open the Diff tab.
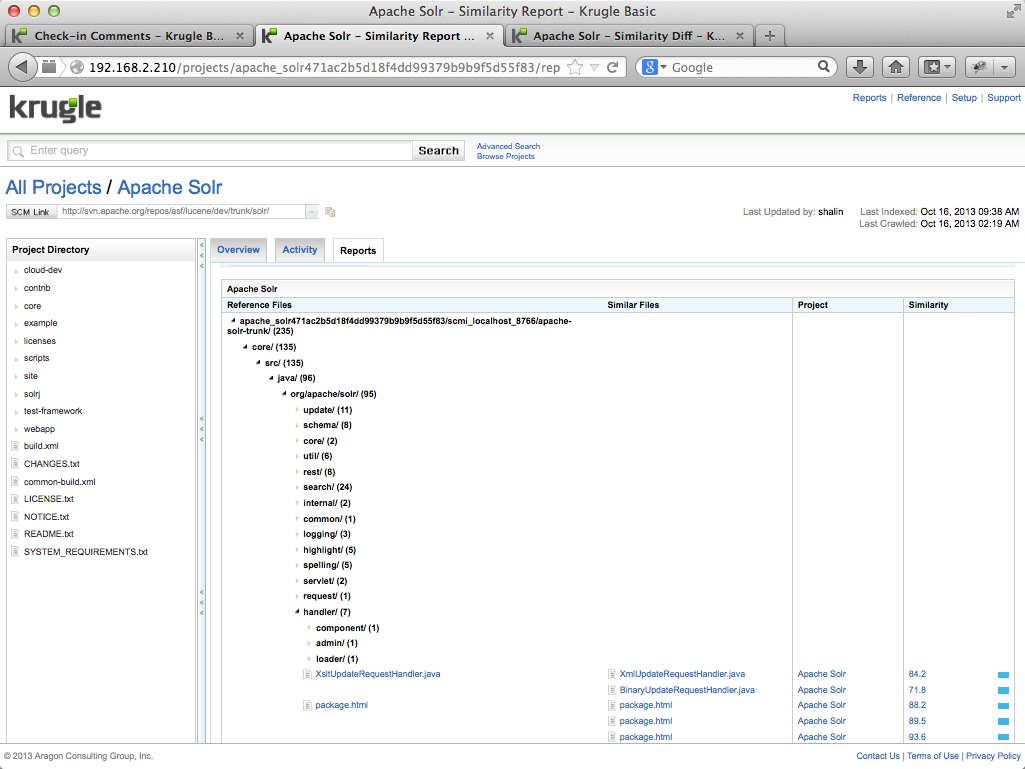
In the example above, we see that files "XsltUpdateRequestHandler.java" and "BinaryUpdateRequestHandler.java" are 71.8% similar (ignoring whitespace and comments). Clicking on the percentage will bring up a diff report that compares the two files in question.
Adding your own code
Now that you are familiar with the key functionality in Krugle Basic, you will be able to search for code, documents and related information within your organization’s projects.
Point of Note
To add, delete or modify projects, you will need to install either Krugle Enterprise or Krugle Basic inside your organization.
You will add (and delete) searchable code projects in Krugle Basic using the administration console. Through the administration console, you will also be able to
To add your own code, consult the Krugle Admin Guide.